Apache
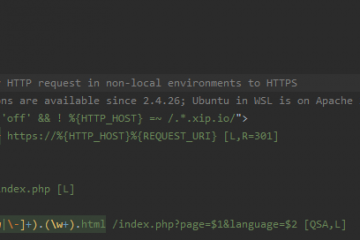
Conditional redirect from HTTP to HTTPS within Apache .htaccess files
Most of the time you are doing local web development without HTTPS and self-signed certificates but good-ol’ plain HTTP. For security and SEO reasons, HTTPS should be enabled in your production environment all the time. One important requirement for production environments is, that every incoming plain HTTP request has to Read more…