Networking
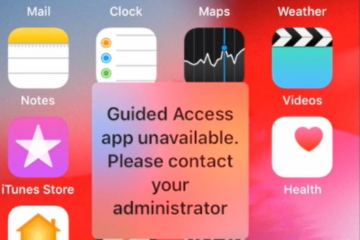
Unknown status LTE_DIA_IP with FRITZ!Box 6850 LTE and Telekom MagentaMobil Business
This is one of those times when I feel pretty stupid.We booked the MagentaMobil Business Speedbox Flex tariff from Telekom for a company event. As the Speedbox wasn’t available and the event was taking place soon, we booked a FRITZ!Box 6850 LTE at short notice. After inserting the SIM card Read more…