Azure
Deploying PHP 8.0 applications with Azure App Service
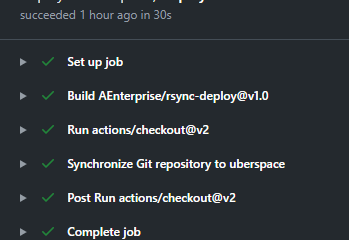
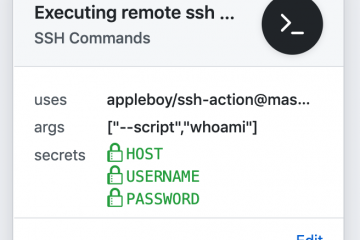
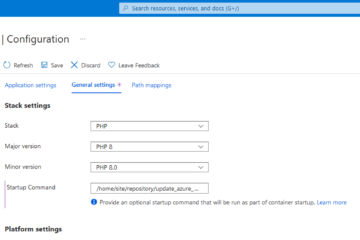
To be able to run PHP applications on Azure App Services which are using PHP 8.0 features, the Runtime Stack has to be changed. With the newer Runtime Stack, you also have to update the nginx.conf of the underlying Docker image. This article describes how you can achieve that. 2023-03-28: Read more…