Microsoft
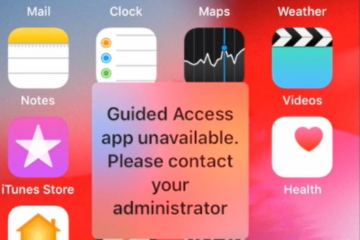
Fixing “Guided Access app unavailable. Please contact your administrator” when using Microsoft Intune and Endpoint Manager
Another problem I had recently asked about, had been a failed iPhone MDM rollout. As in my previous blog post mentioned, the endpoints in the environment – including iPhones – are managed with Microsoft Endpoint Manager. During one of the iPhone deployments, the user received the error Guided Access app Read more…